해당 자료는 김성훈 교수님의 강의를 듣고 정리한 것입니다.
회귀분석
점들이 퍼져있는 형태에서 패턴을 찾아내고, 이 패턴을 활용해서 무언가를 예측하는 분석. 새로운 표본을 뽑았을 때 평균으로 돌아가려는 특징이 있기 때문에 붙은 이름입니다.
Linear Regression
2차원 좌표에 분포된 데이터를 1차원 직선 방정식을 통해 표현되지 않은 데이터를 예측하기 위한 분석 모델. 머신러닝 입문에서는 기본적으로 2차원이나 3차원까지만 정리하면 된다. 여기서는 편의상 1차원 직선으로 정리하고 있다. x, y축 좌표계에서 직선을 그렸다고 생각하면 됩니다.
Hypothesis
Linear Regression에서 사용하는 1차원 방정식을 가리키는 용어로, 우리말로는 가설이라고 합니다. 수식에서는 h(x) 또는 H(x)로 표현합니다.
H(x) = Wx + b에서 Wx + b는 x에 대한 1차 방적식으로 직선을 표현한다는 것이며, 기울기에 해당하는 W(Weight)와 숫자라고 해야하나..그거에 해당하는 b(bias)가 계속적으로 반복되는 과정에서 마지막 루프에서 바뀐 최종 값을 사용해서 데이터 예측(prediction)에 사용됩니다. 최종 결과로 나온 가설을 모델(model)이라고 부르고, "학습되었다"라고 한다. 학습된 모델은 배포되어서 새로운 학습을 통해 수정되기 전까지 지속적으로 활용됩니다.
Cost(비용)
앞에서 설명한 Hypothesis 방정식에 대한 비용(cost)으로 방정식의 결과가 크게 나오면 좋지 않다고 얘기하고, 루프를 돌 때마다 W와 b를 비용이 적게 발생하는 방향으로 수정하게 됩니다. 미분을스스로 최저 비용을 찾습니다.
Cost 함수
Hypothesis 방정식을 포함하는 계산식으로, 현재의 기울기(W)와 상수 (b)에 대해 비용을 계산해 주는 함수입니다. 호출할 때마다 반환값으로 표현되는 비용이 줄어들도록 코딩을 해야 하며, Linear Regression에서 최소 비용을 찾는 함수 입니다.
1. Linear regression - 결과의 범위가 넓다. ex) 점수별로 결과 학습
2. Binary classification - 결과의 범위를 둘로 단순화 시킨다. ex) 합격, 불합격
3. Multi-lable classification - 결과 범위를 단순화 시키지만 두개 이상 있다. ex)학점

1. Linear regression 은 위와 같이 x값 과 y 값 같은 Trainig 데이터를 학습하기위해 그래프로 나타내보면 선형의 그래프에 들어 맞는다는것을 알 수 있다. -> 리니어한 모델의 함수라 예상하고 학습을 시도한다. 위처럼 우리가 가진 데이터는 리니어(선)한 모델일 경우가 많다. (세상의 많은 데이터가 리니어로 설명 할 수 있는 경우가 많다.) 여기서 x와 y 값을 위와같이 점을 찍어서 그 점을 선(일직선)으로 연결한 것이 리니어 레그레이션 입니다. 해당 선이 얼마나 점에게 가까우냐를 구하는 로직입니다.
위의 같은 선으 x가 1일때 y도 1, x가 2일때 y도 2 이기 때문에 Hypothesis는 y=1x 가 됩니다.
여기서 선이 (x,y) 좌표값에서 얼마나 거리가 되는지 확인을 해야되고 이것을 COST 함수라고 합니다.

많은 양의 X,Y 를 가지고 학습하면서 데이터에 맞는 다양한 선을 찾게 된다. 예측한 선과 데이터와의 거리가 멀면 결과가 나쁘고 가까우면 좋은 학습입니다. 그 차이를 식으로 나타내면 로 나태 낼 수 있습니다.

이를 Cost 또는 Loss라고 한다. 코스트(COST)가 음수 일수 있기 때문에 이 값을 재곱 하면 양수로 나타낼수도 있고 코스트 값의 편차를 크개 할수도 있는 장점이 생긴다. 또한 예측 값은 여럿 존재하고 이 값들의 코스트 재곱을 평균값으로 나타낸다면 아래와 같이 나타낼 수 있습니다.
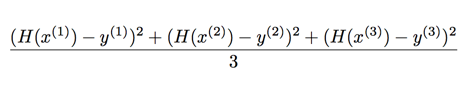


가장 좋은 리니어(선)을 찾고 난 후에 x값일 때의 y값을 예측하는 알고리즘 입니다. 만약 수많은 x값(feature)와 y값(x에 맞는 실제 값, label)의 데이터 셋들이 엄청 많이 학습되었다면 어떤 x 값이 들어왔을 때 y 값은 얼마인가? 학습된 모델에 물어볼 수 있습니다


